 At my other weblog I report on evidence that a sample from Cambodia dated to 100 to 300 AD seems to have considerable Indian ancestry. This is not a result in isolation. Lots of evidence points to non-trivial Indian gene flow. The devil is now in the details of when/who.
At my other weblog I report on evidence that a sample from Cambodia dated to 100 to 300 AD seems to have considerable Indian ancestry. This is not a result in isolation. Lots of evidence points to non-trivial Indian gene flow. The devil is now in the details of when/who.
Second, there is lots of talk about “person X looks like population Y, so perhaps they have ancestry from population Y.” This is almost certainly wrong in most cases.
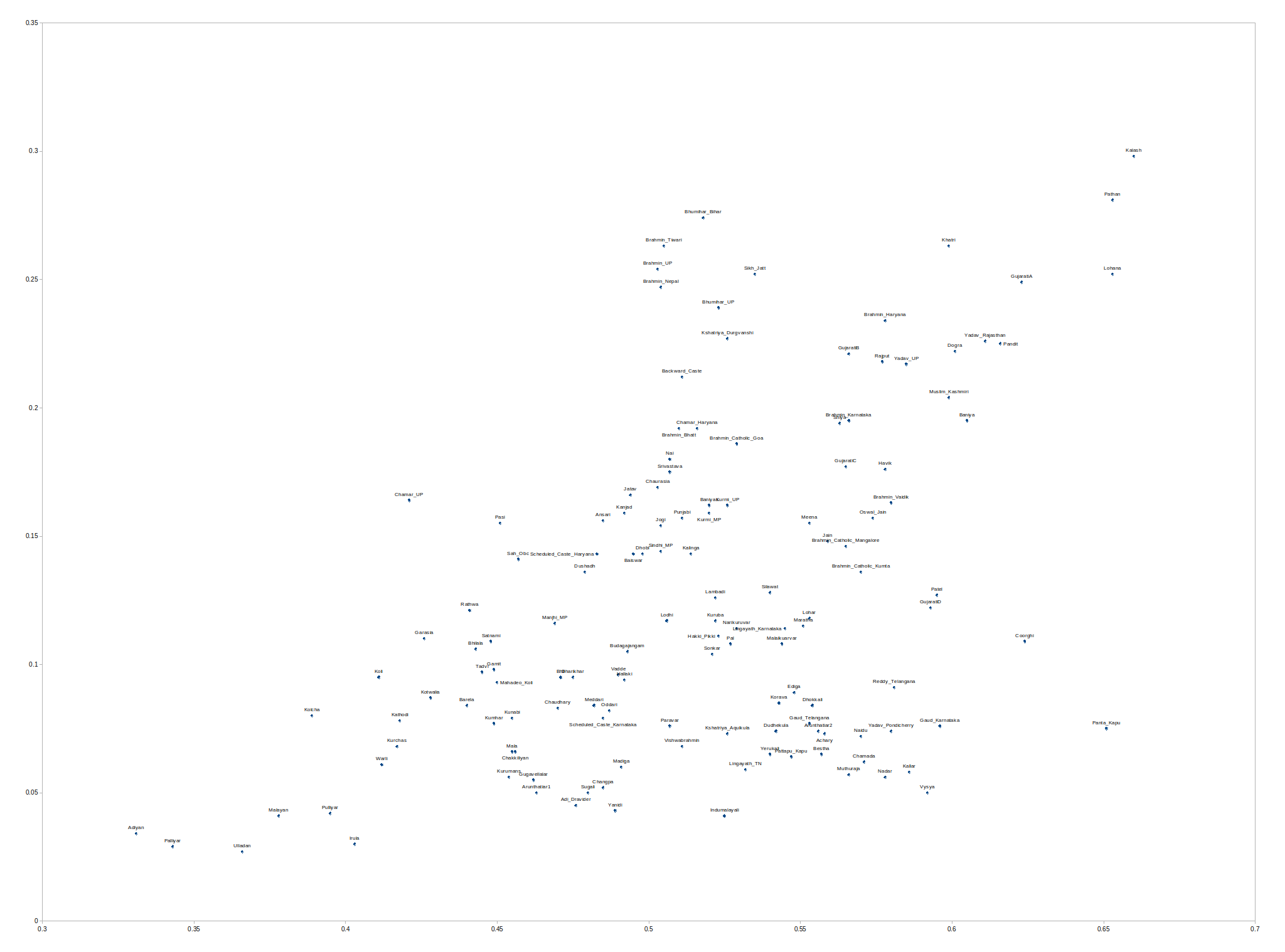
Looking at Indian populations there tends to be far more variation in physical appearance within a population than the variation of total ancestry. In other words, some Tamil Brahmins look like South Indian Tribal people and other Tamil Brahmins look like West Asians. But in terms of total ancestral components, there’s no difference.
The theoretical explanation for what’s going on is that the genetic loci which control “physical appearance” are much smaller in number than the whole genome (on the order of dozens of loci). As such, the sample variance is rather large (the N denominator is small).
South Asian populations differ across each other, but there is usually a quite large within-population variation on genetic variants implicated in physical characteristics. This means that there are a large range and quite a bit of variation.
Though a lot of the discussion involves Muslims, I have heard from multiple non-Muslim people of Northwest Indian stock (e.g., Pandits) that they must have “Persian ancestry” because they look so Persian. The genetics refutes this rather strongly. Rather, modern Persians and many Northwest Indians share deep ancestry which diverged after the Last Glacial Maximum 20,000 years ago.
 In my view a level 5 PISA score is the minimum requirement for a person to be considered a high school graduate who is literate in math, able to function in the modern global economy, or be qualified to attend college. The PISA report defines a level 5 PISA score or better as a fifteen year old that “can model complex situations mathematically, and can select, compare and evaluate appropriate problem-solving strategies for dealing with them.”
In my view a level 5 PISA score is the minimum requirement for a person to be considered a high school graduate who is literate in math, able to function in the modern global economy, or be qualified to attend college. The PISA report defines a level 5 PISA score or better as a fifteen year old that “can model complex situations mathematically, and can select, compare and evaluate appropriate problem-solving strategies for dealing with them.” 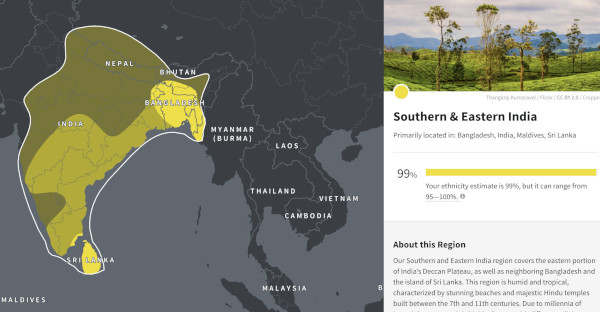
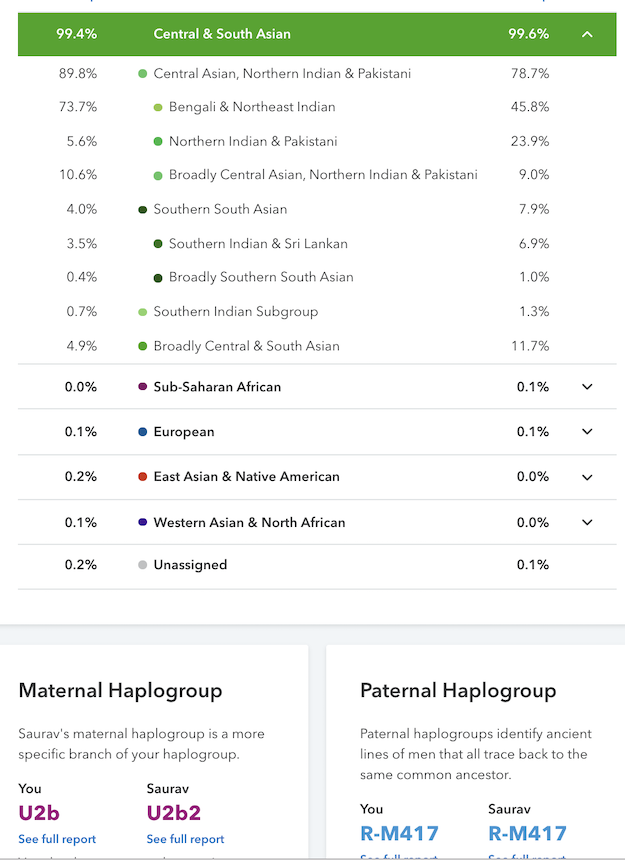
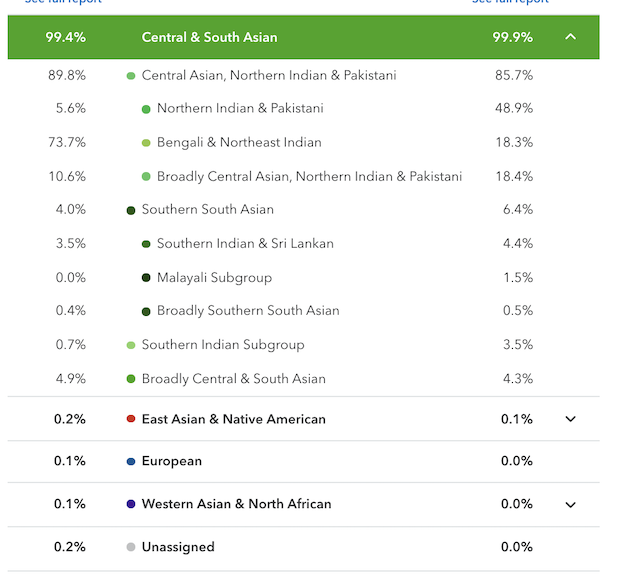
 Recently I made a comment that I appreciate what 23andMe and Ancestry have done with their South Asian ancestry updates. My own results came into sharper focus. The algorithms did what they were supposed to do.
Recently I made a comment that I appreciate what 23andMe and Ancestry have done with their South Asian ancestry updates. My own results came into sharper focus. The algorithms did what they were supposed to do.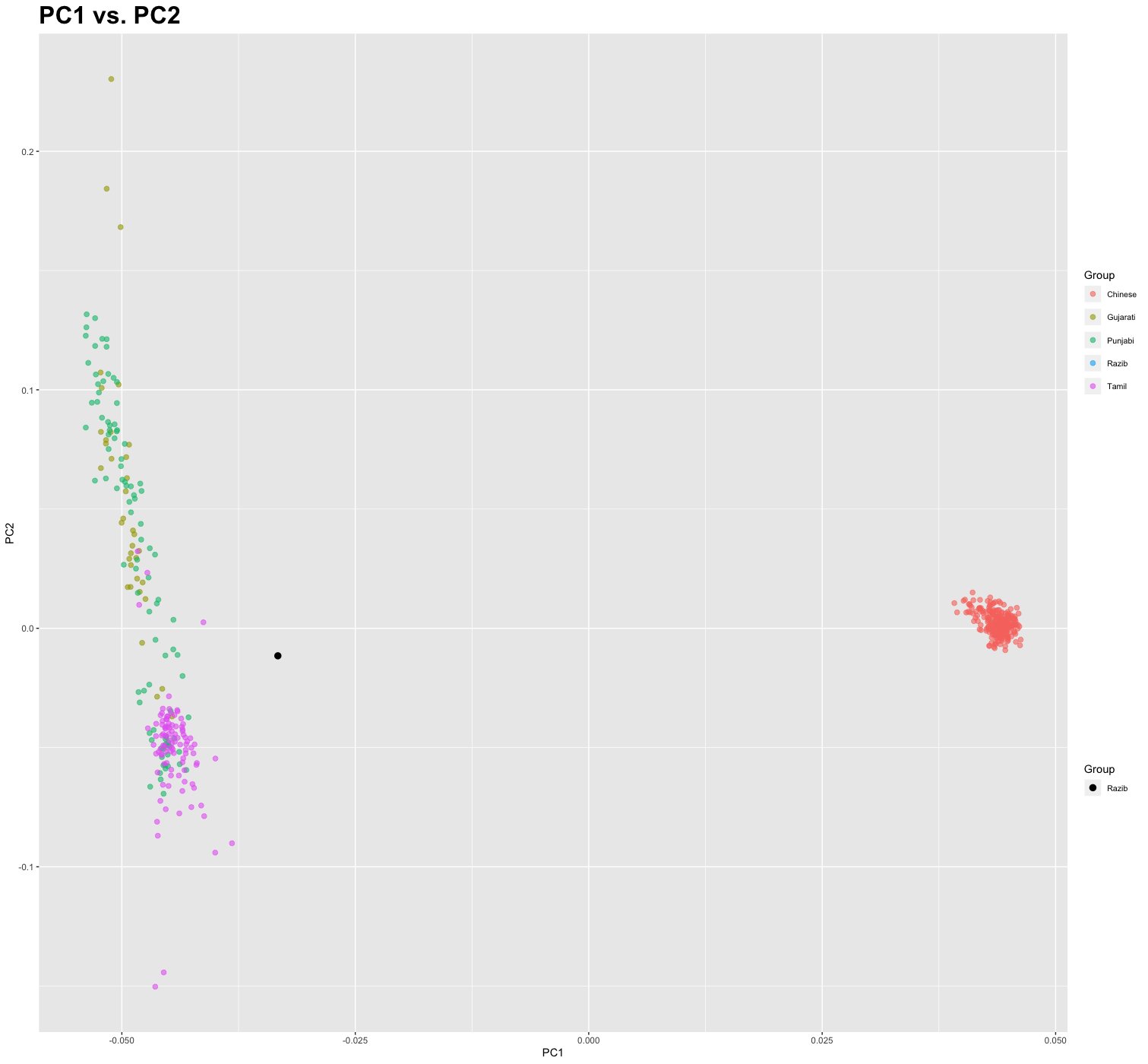
{kind=link}