
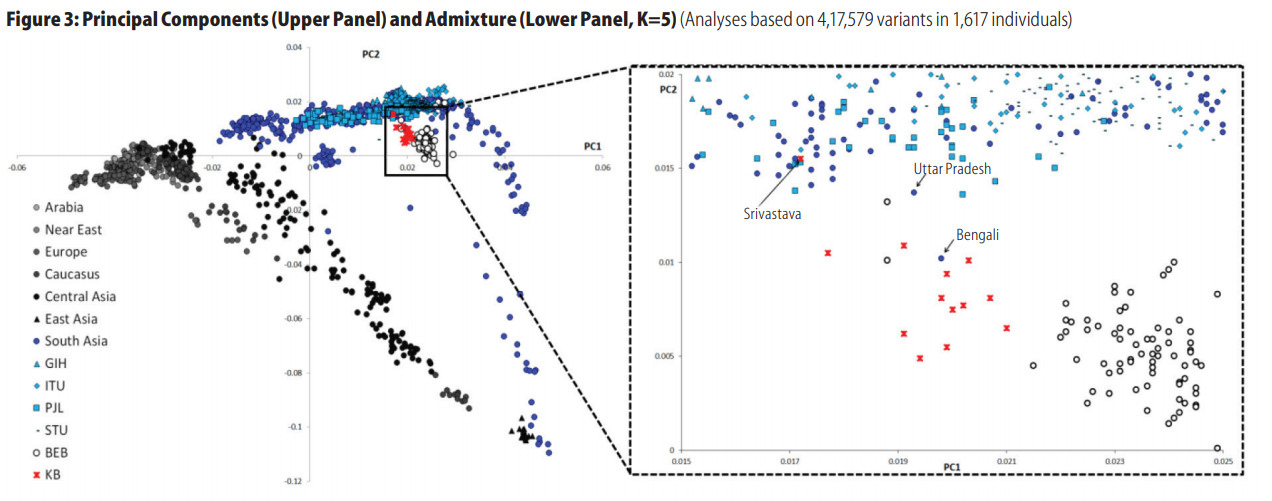
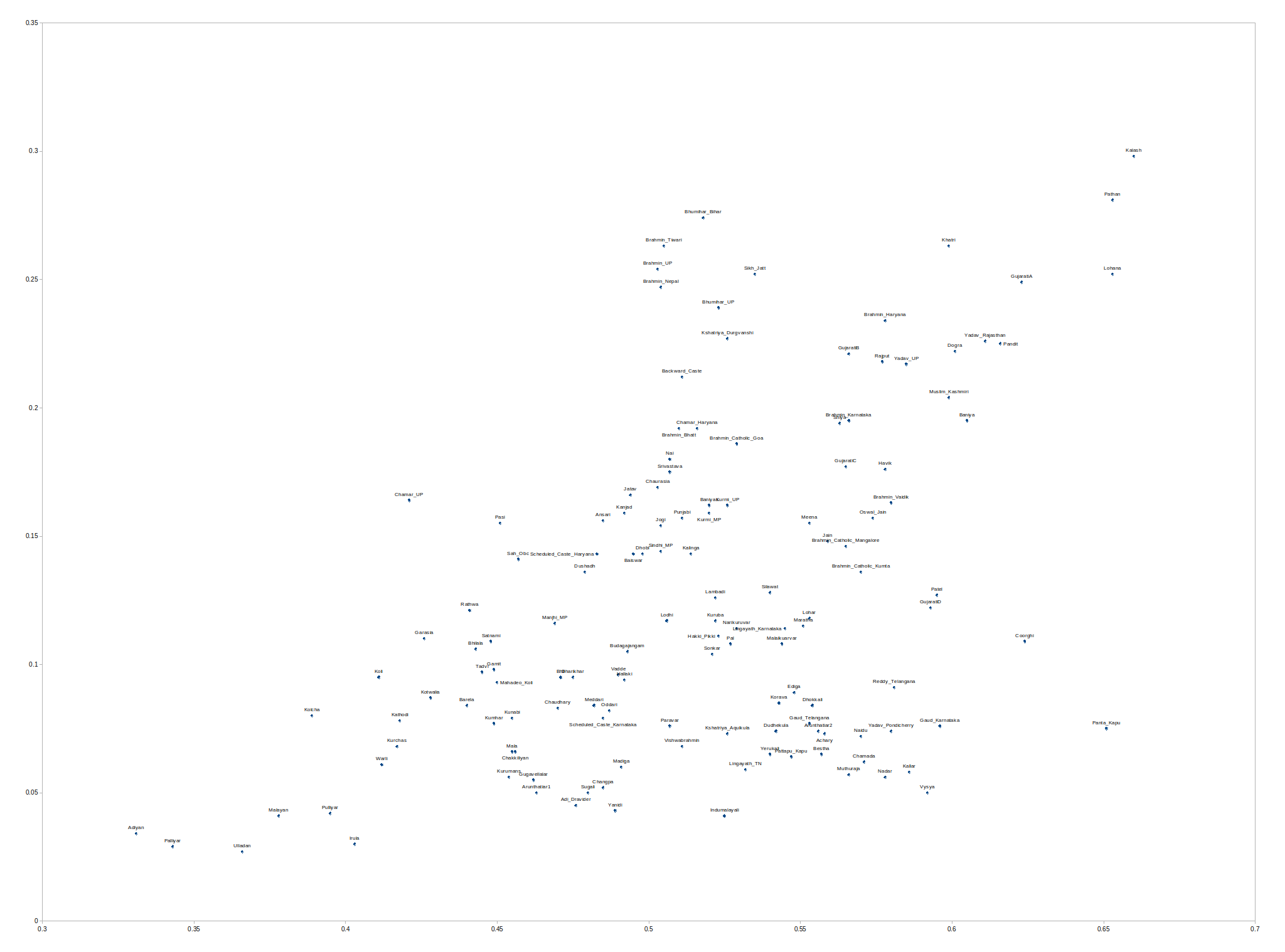
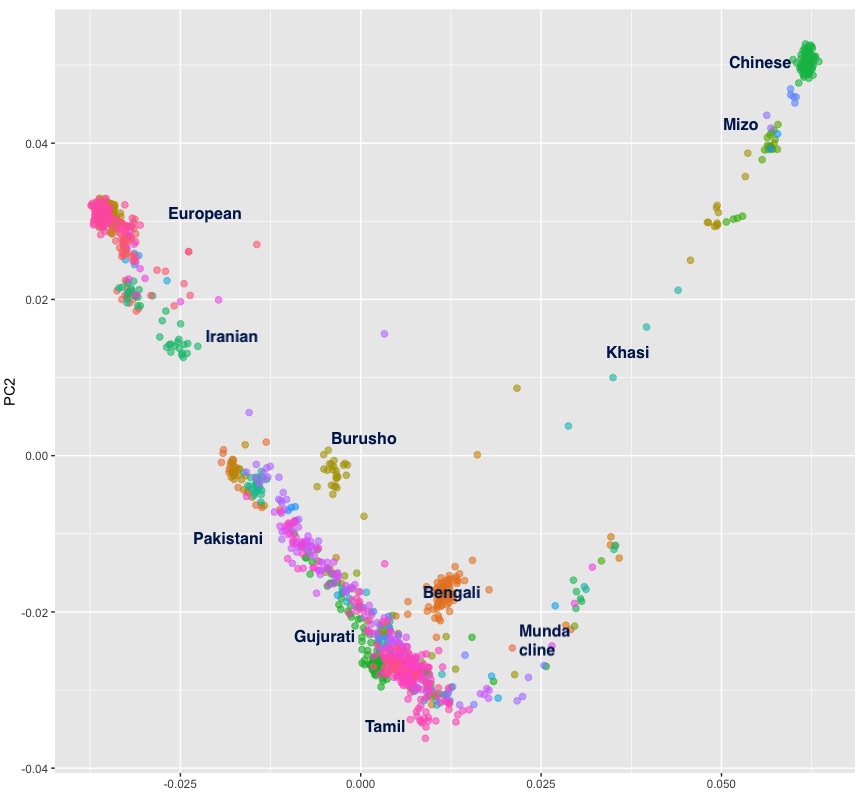
A few years ago there was a short paper that analyzed genotypes from some Kulin Kayasthas from West Bengal. The plot above illustrates what you really need to know. The Kayasthas are positioned on the PCA right between East Bengalis and people from the main India cline, with a slight shift toward more ANI.
I’ve looked at a few West Bengal Kayasthas myself, and that’s what I always see. When I look at individuals from Bangladesh, the ones with the most East Asian ancestry are invariably from the furthest east. So it looks like going from eastern Bengal to western Bengal there is progressively less East Asian ancestry. And, unlike Bengali Brahmins, Bengali Kayasthas do not seem to be that different from generic Bengalis as such. In contrast, Bengali Brahmins tend to have a strong shift toward Uttar Pradesh populations and look very similar to Uttar Pradesh Brahmins with a minority non-Brahmin Bengali admixture.
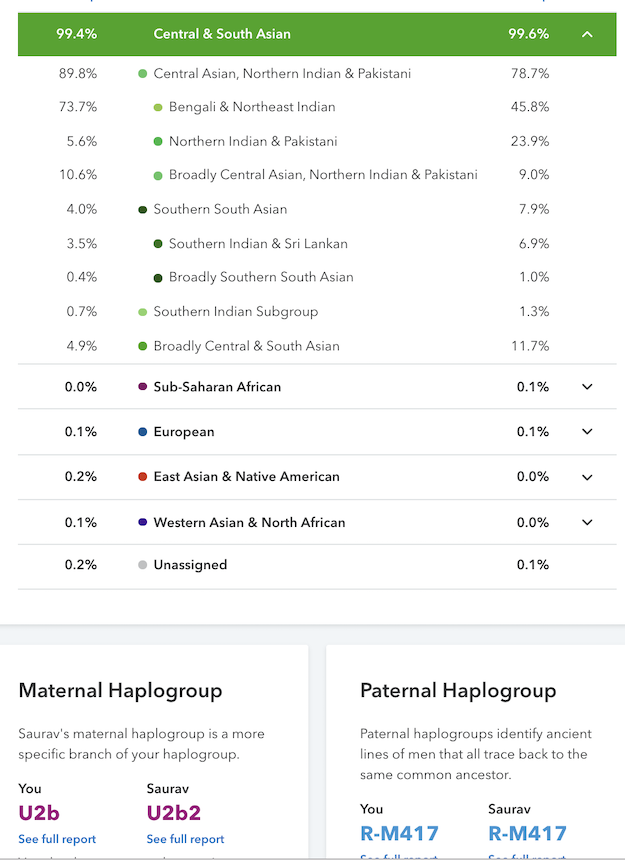
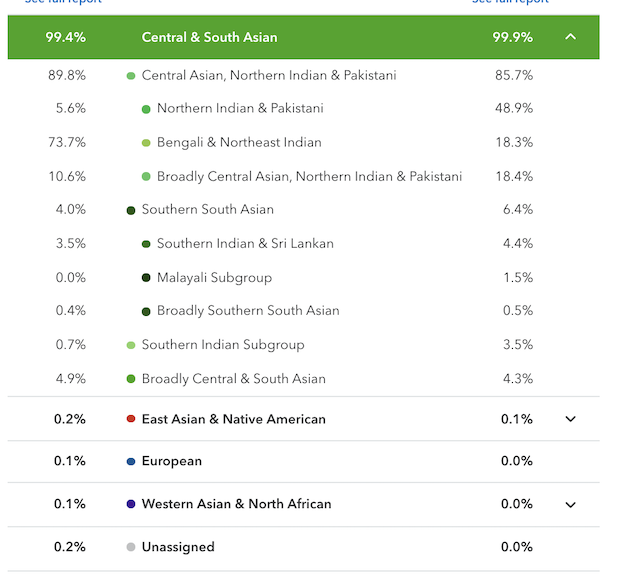
Finally, take a look at the Y and mtDNA. Though R1a is overrepresented, one of the Kayasthas has both male and female East Asian uniparental lineages.

{kind=link}