 Recently I made a comment that I appreciate what 23andMe and Ancestry have done with their South Asian ancestry updates. My own results came into sharper focus. The algorithms did what they were supposed to do.
Recently I made a comment that I appreciate what 23andMe and Ancestry have done with their South Asian ancestry updates. My own results came into sharper focus. The algorithms did what they were supposed to do.
Both of the companies found that I’m probably Bengali. 23andMe, with its massive database, and SVM framework, even narrowed down where in Bangladesh my family is from.
Both my parents are from Comilla. More specifically, my mother’s family is from Homna (though her maternal grandfather was from Noakhali by origin). When I was small I was sent to stay with my mother’s relatives in Sreemudi village, which I can now find on Google maps! My father’s family is from just outside of Chandpur. Basically, my family hails from the lower reaches of the Meghna river. And more precisely, the eastern shore of the Meghna.
And yet this analysis is missing something. The term and category “Bengali” has implicit within it other phenomena. I generated a PCA which illustrates this well:
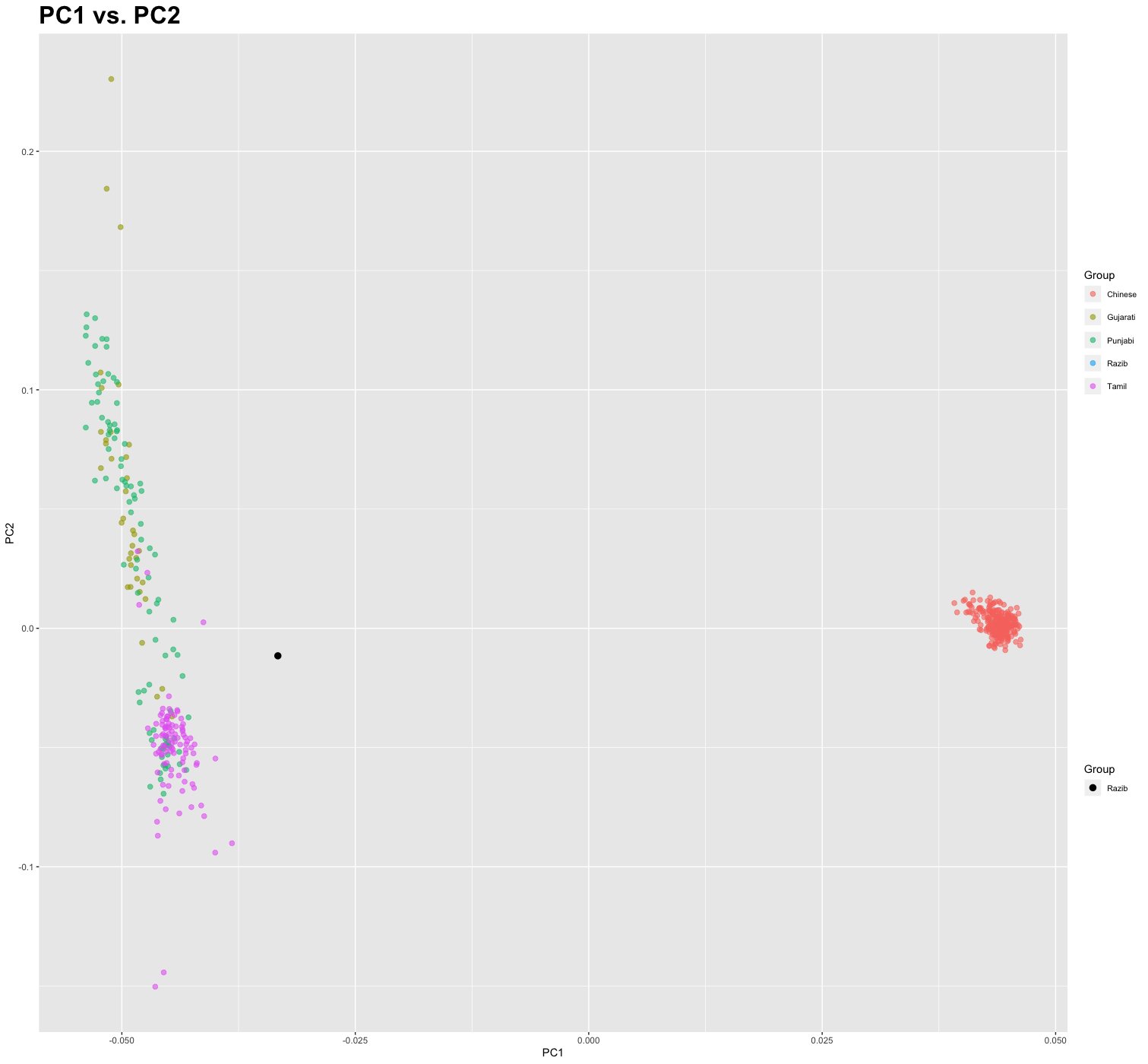
You can see I’m pretty clearly shifted toward East Asians. That’s because that’s common in Bengalis. That seems like it’s interesting information people would like to know. But simply creating a “Bengali” category masks all that.
Speaking of genetics, I finally got around to playing around with qpAdmin. People keeping asking me Bengali percentages of the various ancestral components in the recent Reich lab India paper. Well, I ran the same model (mostly, not exactly sure of all the samples….), and got some results.
| IndusValley | Steppe | AHG/AASI | EastAsian | Birhror (Munda) | |
| Bengali | 0.448 | 0.126 | 0.301 | 0.125 | |
| Punjabi – Lahore | 0.58 | 0.2 | 0.192 | 0.03 | |
| Tamil – Sri Lanka | 0.57 | 0.07 | 0.38 | -0.025 | |
| Gujarati | 0.59 | 0.18 | 0.21 | 0.03 | |
| Telugu | 0.595 | 0.085 | 0.33 | 0 | |
| Birhor | 0.27 | 0 | 0.49 | 0.24 | |
| Bengali | -0.163 | 0.142 | -0.86 | -0.364 | 2.25 |
| Bengali | 0.264 | 0.136 | -0.075 | 0.675 |
The “Bengali” sample is from the 1000 Genomes. You can see that 12.5% of the ancestry is “East Asian”. These are Dai. The AHG are modeled as being related to the Andamanese as per the Reich lab paper, and Indus Valley are the pooled IndPe samples. Steppe are Sintashta.
I ran the other 1000 Genomes samples with the same model. The -0.025% for Tamils for East Asian is that this model is really not necessary for them. I kept the East Asian in there to compare apples to apples with the Bengalis.
I also looked at Munda population, the Birhor. The results align perfectly with what we know. The Munda have no steppe ancestry. But, they have a lot of East Asian ancestry. One hypothesis for Bengalis is that they have Munda ancestry. But when I add them to the model you can see the results are crazy. If I swap out the East Asians with the Munda the results make some sense, but standard errors are way higher than in the model with the Dai/East Asians.
Basically, Bengali (Dhaka) samples have East Asian ancestry that’s more like populations to their east, and not like the Munda to their south and west.
What does it mean ‘Northern Indian/Pakistani’? What does it mean ‘Broad Central Asian’? What does it mean ‘Broadly Southern South Asian’? It seems meaningless so as the term ‘steppe’ or ‘indo-germanishe’. Why don’t use the basic genetics haplogroup – R1a, O, etc, etc?
Anyone with any percentage of R1a I consider 100% Serb unless he/she rejects this. In this case – no dramas, bon voyage, have a nice life. Even, those without any percentage of R1a, can be Aryans for me, this is primarily a cultural thing, not genetics.
“Southern south asian” most probably means people from Sri Lanka and the Maldives.
Btw it seems that most indians don’t believe in Aryan migration.
Are these genetic clusterings done on the basis of ancestry percentages?
BTW Try to write also about Assamese and Afghan genetic make up
Assamese might be Bengali+10-15% additional East Asian? Their facial features vary a lot, some look Bengalis and some look East Asian and many something in-between.
Afghan Pashtuns same as Pakistani Pathan? :
AHG InPe Steppe
0.067 0.653 0.281
Afghan Tajiks have much higher steppe, they also have some East Asian and lil bit to none AHG compared to Pashtuns.
Are these genetic clusterings done on the basis of ancestry percentages?
it’s based on f4 stats. but yeah.
My own experience of Telugu: there is good amount of southeast asian ancestry, strangely even melanesian. We can also make out by the phenotype. Most of this imprint in my experience is limited to the coastal AP.
Does anyone here with expertise or knowledge know why South Indians or Telugus apparently seem to have Melanesian admixture? I took Ancestry DNA test and found about 8 to 10% Melanesian contribution.
8-10% seems to be just due to the fact that the AASI/aboriginal/indigenous component of south asian ancestry has a deep relationship to australo-melanesians. some of the reference panels don’t have the enough variation to catch enough of that shared variance within indians, so they are caught by the melanesian reference samples.
does that make sense?
Got it, thanks!
Btw the melanesian component appears to ingrained itself in 1700s or so.
IndusValley Steppe AHG/AASI EastAsian
Bengali 0.448 0.126 0.301 0.125
Tamil–Sri Lanka 0.57 0.07 0.38 -0.025
I think the Sri-Tamil numbers would be broadly the same for the sinhalese too.
A little less Indus and little more AHG/AASI.
Even though this individual does not East Asian, it is there and most likely notthru the purported Bengali connection.
Even in Jaffna there have been Javanese settlements. eg Chavakacheri Chavaka=Java a town in Jaffna.
In around the 12th century the Culavamsa and the Yalpana Vaipava Malai record the invasion by Chandrabanu of Javaka.
The Yalpana Vaipava Malai records that Chankili I (1519–1561) chased out the Malays (and Sinhalese) from Jaffna
Extract from Yalpana Vaipava Malai (VijayVan and Vijay might find this interesting)
https://imgur.com/N22BVbY
Chandrabanu of Java
https://en.wikipedia.org/wiki/Chandrabhanu
Hi Sereno
Thans for the ref.
The Yalpana Vaipava Malai (Jaffna Glory garland) says :
“For some time past the Parangis frequented Mannar for purposes of trade. They first came to Langha in the year Parithapi corresponding with the SaJca year 1428, in the reign of king Paralc-kirama-vahu of Kotta, and having obtained his permission they commenced to trade in his territories, and by degrees extended their trade to this kingdom also. It was a sworn duty among the Paranghis to endeavour to spread their religion wherever they went. By the force of their preaching number of families embraced the Saththiya vetliam at Mannar. As soon as Sanghili heard of this conversion be put six hundred persons to the sword without any distinction of age or sex. This took place in the month of Adi of the year Kara. His insane fury longed for more victims and he fell upon the Buddhists. The followers of Buddhism, were all Singhalese, and of them there were many in this kingdom. By an order which he issued he expelled them beyond his limits and destroyed all their numerous places of worship. They betook themselves to the Vannis and the Kchyidiyan territories, and not one Singhalese remained behind nor ever after returned hither.
In the reign of Vijaya Bahu (the usurper) there was
a. numerous army of Yavalcar in the king’s pay. Their numbers underwent constant diminution by deadly feuds among themselves and by the oppression of kings. The remnants of them inhabited the villages of Savakach-cheri and Savang-kodu But Sangkili drove them also out of his kingdom”
Parangis (Firangis in Turkish – standing for Franks) refer to Portugese missionary activity after Da Gama and Francix Xavier landed in India and started militant conversion. Sangilis response was equally ferocious – kill the converts. And he also seem to have expelled the so called Chavkar i.e. Javanese
By the time of Sangili , Javakar i.e. javanese , it may refer to anyone from south east Asia , seem to have been there for a few hundred years. Does it mean they lived as a caste and married local women. These Javanese seem to have been absorbed among both Tamils and Sinhalese , who themselves are not water tight compartments historically . There have been ethnic switches – you should know it better 🙂 . Usually in South Asia castes which are formed disparate ethnic elements survive for a long time. In fact , caste itself is a mechanism for ethnic survival. I am surprised there are no remnants of the Javanese in Srilanka today
By the time of Sangili , Javakar i.e. javanese , it may refer to anyone from south east Asia , seem to have been there for a few hundred years. Does it mean they lived as a caste and married local women. These Javanese seem to have been absorbed among both Tamils and Sinhalese , who themselves are not water tight compartments historically
It is possible that group came in the 13th century or so. Most likely Buddhist or Hindu, there is no indication of they being Islamist. Looks like they got absorbed into the local population, probably easy enough if they were Buddhist or Hindu.
We do have a very small 0.2%/40K self identified population called Malays in English and Ja in Sinhalese.
They came in during Dutch and British times. They are extremely over represented in the Armed forces and Police and in Rugby.
Some still look distinctively SE Asian, other run of the mill Sri Lankan. Like the wiki says they are going to disappear by being absorbed.
They have surnames like Doole, Kitchilan. Most surnnames ending in Bangsa/Bongso, Deen/Dean are Malay. The first name, Tuan is an honorific also indicates malay. An unusual one is Weerabangsa where just a single letter switch makes it the Sinhalese Weeravansa/Weeravamsa
https://en.wikipedia.org/wiki/Sri_Lankan_Malays
Sometimes, not obvious it is a Malay surname. That these were Malays was new even to me, Jurangpathy, who would imagine Amrit Singalaxana is Malay
https://en.wikipedia.org/wiki/List_of_Sri_Lankan_Malays
When in school dated a Malay, Rehana. Just sneaked to a few movies. Two of my Sinhalese classmates are married to Malays and their children are Sinhalese.
Tamils and Sinhalese , who themselves are not water tight compartments historically . There have been ethnic switches – you should know it better
Ha, ha no question, also plenty of that I know of that happened in my life time.
Thanks for running the qpAdmin and including Bengalis – makes intuitive sense.
The steppe:InPe seems relatively high however in comparison to other populations.
On the assumption that the local pre steppe populations may have been (Munda like) – high AHG:InPE +/- E Asian, do you think there are any implications in the above ratio?
Regarding the Bengali component hiding the East Asian pull – very valid, but I guess a similar principle applies to the very generic Northern Indian & Pakistani ie Bihar to Punjab hiding any NW pull.
I’ve collated about 90 various Bengali composition results from 23andme broken down by region on the below link:
https://docs.google.com/spreadsheets/d/17CaTr2CI8nS86EJIl-oMUt-NZXNdxCINcdykXlqES54/edit#gid=1593095722
Interesting results. What are your uniparentals?
All of the places mentioned in the post are not too far from Tripura.
“My father’s family is from just outside of Chandpur.
Basically, my family hails from the lower reaches of the Meghna river. And more precisely, the eastern shore of the Meghna.”
Brahmanbaria is right next to Homna, Both Chandpur and Brahmanaria once were part of greater Comilla.
“Well, I ran the same model (mostly, not exactly sure of all the samples….), and got some results.”
I assumed Bengalis would have slightly higher Sintashta, as Chamar_UP scored 0.164 Steppe in the table from “The formation of human populations in South and Central Asia”. I compared them in global25 nMonte :
“sample”: “Bengali_Bangladesh:Average”,
“fit”: 1.2906,
“Sindhi”: 33.33,
“Punjab_Ramgharia”: 32.5,
“CustomGroup_Simulated_AASI”: 24.17,
“Dai”: 10
“sample”: “Chamar:Average”,
“fit”: 1.3448,
“Sindhi”: 54.17,
“CustomGroup_Simulated_AASI”: 43.33,
“Punjab_Ramgharia”: 2.5,
“Dai”: 0
Bengalis prefer both Sindhi and Punjab_Ramgharia while Chamars only Sindhis. Ramgharias looks more Steppe shifted than Sindhis, So Bengalis must have slightly higher steppe than what Chamars score?
“Basically, Bengali (Dhaka) samples have East Asian ancestry that’s more like populations to their east, and not like the Munda to their south and west.”
Perhaps the pre-Aryan population in Bengal delta were Dai-like and not Munda? It might’ve not been very populated back then. I surmise folks living in tribal heavy states in central and central-eastern India might have actual Munda ancestry, including Bengalis from West Bengal near Jharkhand border.
“Perhaps the pre-Aryan population in Bengal delta were Dai-like and not Munda?”
If that was the case, east asian ancestry in Bangladeshis would be much higher…much higher than AASI ancestry
The population possibly was low given Bengal delta was full of forests and swamps back then. We don’t know which community lived there, but now that we know Bengalis don’t have much Munda-like ancestry I’m sceptical about an AASI-enriched group had been living there. Santhal tribes found in North Bengal might have migrated later from central-eastern India. The AASI ancestry in Bengalis is the same found in Gangetic plain communities, Bengalis have a slightly lesser quantity compared to non-Brahmin Gangetic plain groups. More west you go from Bangladesh to Gangetic plain, both Iran_HG/Steppe:AASI increase in non-brahmin non-Dalit groups.
the results in admixture timing indicate something happened 1,500 years ago with the ancestors of modern bengalis. that’s when the s. asian + e. asian came together.
Samatata was a province of Mauryan empire thus most likely proto-Bengalis(without any east Asian admixture) have been living in Bengal delta before contact with dai-like groups. Genetically the same as non-brahmin non-Dalit Biharis. What about non-brahmin non-Dalit samples from Orissa? They might be a closely related group as they speak a closely related language.
What kind of a mix was this? We know that the southeast Asian ancestry in the Munda is overwhelmingly male derived. Is this one the same or is it comparable on both paternal and maternal sides?
So do non brahmin west bengalis have higher steppe and higher iran_HG than Bangladeshis?
i thought that they had a bit higher AASI.
Or is the difference very slight?
What is their genetic make up?
Btw what is the percentage of west asian ancestry in bangladeshis? I am pretty sure that it would be little.
the difference is slight if you remove the e. asian ancestry. they may have a bit more steppe idk. need more samples. all the ones i get are kayastha.
“Btw what is the percentage of west asian ancestry in bangladeshis? I am pretty sure that it would be little.”
If by west Asian you mean Arab, it’s completely nonexistent. With Persians we have that Iran_HG link, but not any recent contribution. Our steppe and East Asian also look different from Turkic Central Asian. And Pathans are genetically part of south Asian cline. Islamic rule in Bengal didn’t affect genetically; it seems.
is it common that a region has such asymmetry between the diversity of male and female lineages? Aka is S Asia just an exceptionally cucked place or is this just the norm